Content
Everything 这个工具相信大部分人并不陌生,它支持在 Windows 上进行迅速的全盘的文件/文件夹名称搜索,并且它支持多种搜索语法和筛选条件,性能也比较强大。唯一的缺点是依赖 Everything 服务或管理员权限,在较长时间不运行后重新启动需要一段时间的索引更新
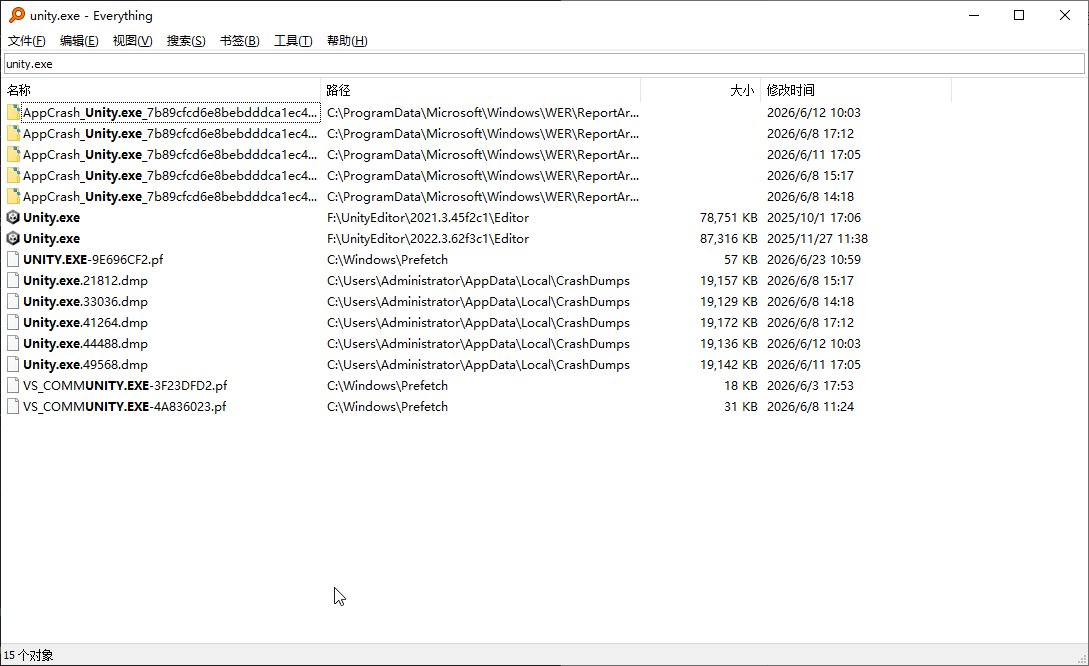
但这么好的工具 AI 不能使用岂不是太可惜了,Everything 提供的可执行文件本身也不支持命令行式调用。并且在使用 Codex 等 Agent 处理 Windows 疑难杂症的过程中,也常常看见 AI 因为需要寻找某文件而进行地毯式搜索。
万幸的是,Everything 官方提供了命令行搜索工具 ES ,在命令行上支持与 Everything 类似的筛选、搜索、排序、导出等功能。
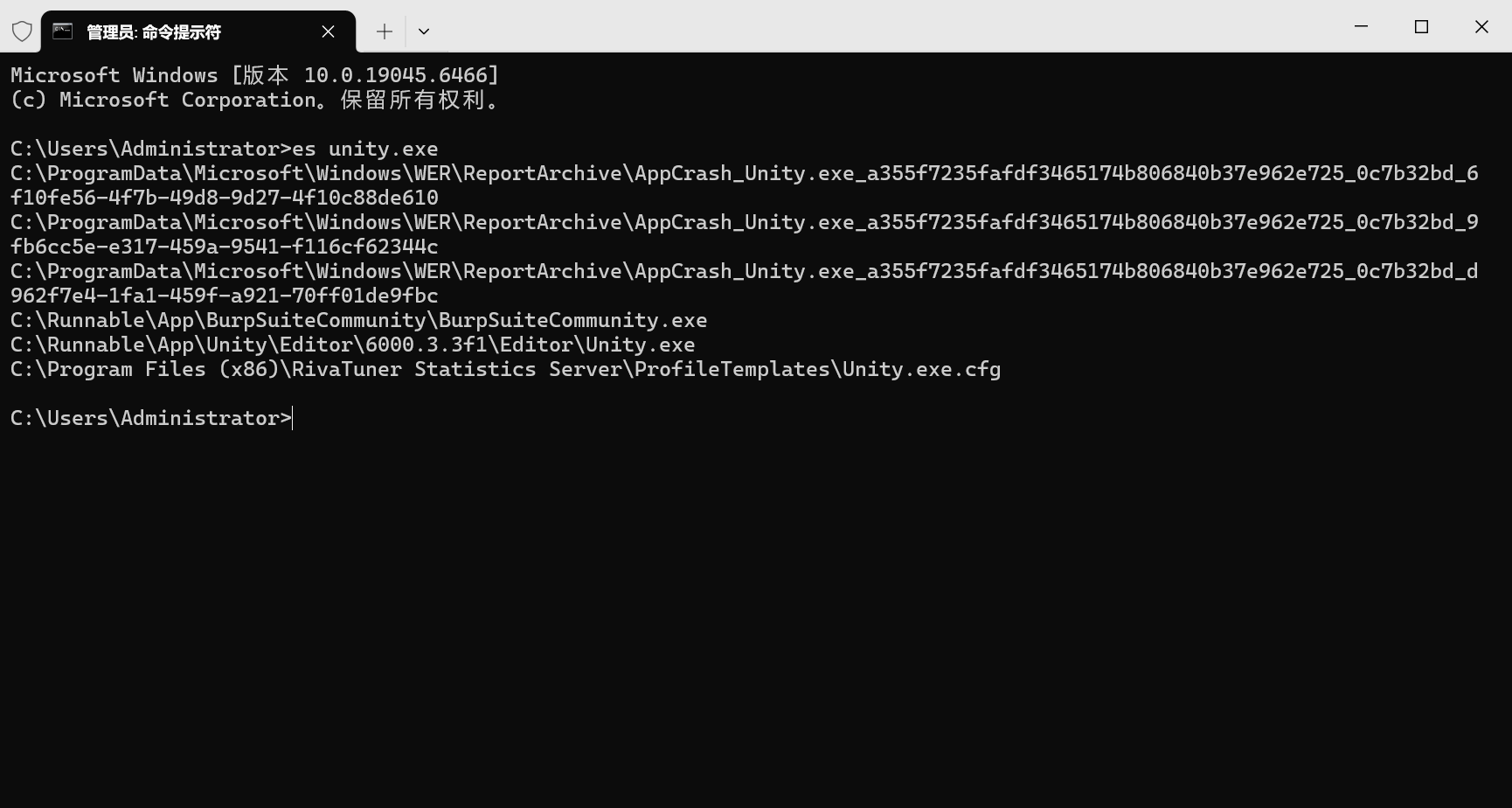
但是,ES 本身依赖 Everything 进程并通过 IPC 与 Everything 通讯,这导致在使用 ES 时要求 Everything 已经在运行。并且 ES 不能跨用户访问 Everything,这导致例如 Codex 这样的工具必须在提升环境下才能正常使用 ES。